In part I of the blog on this topic (http://oracledataviz.blogspot.com/2020/04/how-to-retrieve-valuable-information.html), we talked about the
various data mining views that store information about every ML model that gets
created in the Oracle database. These views have information about ML models size, models settings, attributes used in the models etc. This information is
available for each ML model created in the database irrespective of the mining
function or the algorithm used.
We also talked about one particular view called ALL_MINING_MODEL_ViEWS which contains the names of all the underlying model views that gets created
behind the scenes every time we create an ML model. The number and kind of
views that get created differ from one algorithm to another. An ML model built using Naive Bayes algorithm will have a
set of related model views. An ML model built using Decision Tree will have
another set of related model views created and so on.
In this blog, let’s look at these specific model Views that get created for different algorithms.
Let us consider the same Sample Problem
discussed in Part I of the blog which is to determine a customer’s response to
an affinity card program. Let’s build an ML model called DT_TEST using Decision
Tree algorithm. (Refer to Part I for Model training syntax details).
Once the model is created, if you query ALL_MINING_MODEL_ViEWS for the model_name as DT_TEST, you will
find that the following underlying views have been created.

These view names have a fixed format. It begins
with DM$V followed by an alphabet that is specific to the model view followed
by the model name. DM$V<Alphabet><Model
Name>.
Let’s look at some
of these views, see what information they contain and how to visualize them using
Oracle Analytics.
a) DM$VCDT_TEST – This is the scoring cost view and
describes the scoring matrix for classification models. The view has actual_target_value,
predicted_target_value and cost.
Conclusion
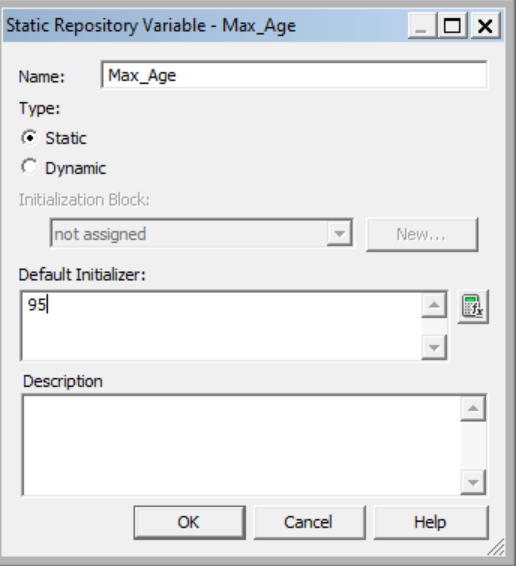
x
Conclusion
x

b) DM$VGDT_TEST - This view describes global statistics related to the model build like number of rows used in the model build, convergence status and so on.
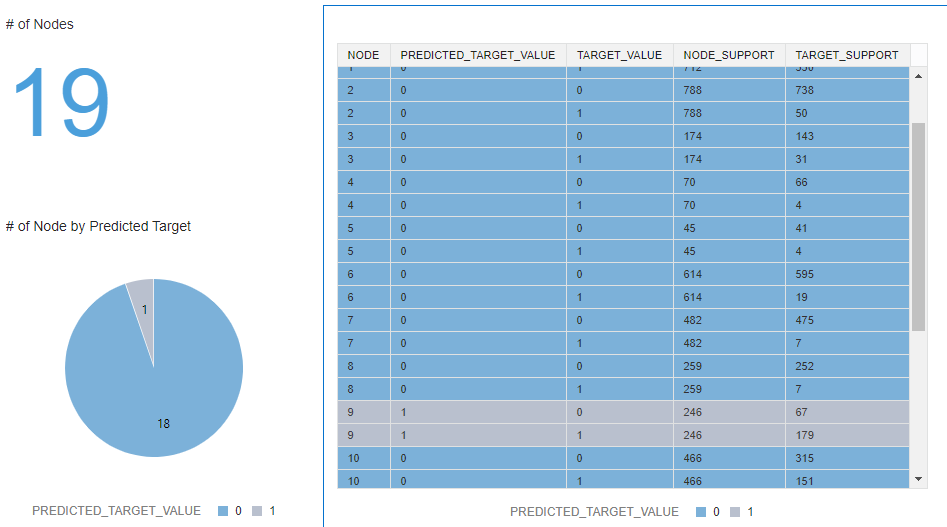
c) DM$VIDT_TEST - This is the node statistics view and describes the statistics associated with individual nodes in the decision tree. The statistics include a target histogram for the data in the node. For every node in the tree, this view has information about predicted_target_value, actual_target_value and node support.
Here's a sample visualization of this information for the DT_TEST model that resulted in a tree with 19 nodes.
d) DM$VMDT_TEST - This view describes the cost matrix used by the decision tree build.
e) DM$VODT_TEST - This view contains the high level node description. It contains the Node and Parent information that allows us to understand the hierarchy of nodes. For every node, there is information about the attribute associated with the node, operator (IN, > , <> etc) and the attribute value. The attribute value is stored as an XMLTYPE in the view. In order to visualize it within Oracle Analytics, extract the string value from the XML in the data set creation similar to what's shown below.

Once the data set is available in Oracle Analytics, a tree diagram helps in understanding the hierarchy of nodes in the decision tree. Attribute details about each node is also available in this view providing more insight about attributes that are relevant in the input dataset.

f) DM$VPDT_TEST - This is the split information view and describes the decision tree hierarchy and the split information for each level in the Decision Tree. For each node in the tree, this view has details about the attribute associated with the node and the split type (Main/Surrogate).

g) DM$VSDT_TEST - This is the computed settings view and lists all the algorithm computed settings as a name-value pair.
h) DM$VTDT_TEST - This is the target map view and describes the target distribution. The view contains target_value, target_count and target_weight information.
i) DM$VWDT_TEST - This is the alert view and lists all the alerts issued during the model building process.
While a Decision Tree model results in a specific set of views , a Naive Bayes model called NB_TEST will result in a slightly different set of views as shown below.

Conclusion
Oracle Database maintains a lot of valuable information in several dictionary views when a mining model is built. The information in these views helps in understanding several aspects like what attributes are important in the input data set, what is the distribution of the target value, details about the model that can help in iterative-ly improving the overall accuracy of the model predictions and so on. Oracle Analytics helps in visualizing all this information in an intuitive and interactive manner.